
ChatGPT and I have trust issues: testing LLMs, the playbook – Part One
If you don’t live under a rock (or in a pineapple under the sea) then you have most likely heard of, been affected by, or tried out ChatGPT, Bing Chat, or Bard.
If you don’t live under a rock (or in a pineapple under the sea) then you have most likely heard of, been affected by, or tried out ChatGPT, Bing Chat, or Bard. These and many more large language models (LLMs) have been unleashed to the public and can perform a wide variety of tasks from generating text to writing code, and the results are impressive!
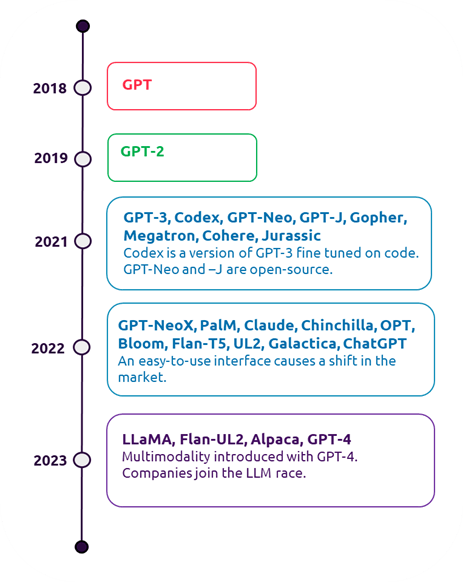 The rise of large language models over the last 5 years.
The rise of large language models over the last 5 years.Although exciting, there is also a darker side to these models. Italy has been the first western country to ban the use of ChatGPT over data privacy and potential GDPR compliance issues. As these models become more complex and more accessible to the public, it is important to ensure that they are lawful, reproducible, fair, robust, and safe.
In this two-part blog post, we will explore a testing framework for LLMs and cover some of the testing methods that will help in detecting and mitigating potential issues and risks to ensure a quality solution.
Testing framework for LLMs
To build a testing framework for AI, historically we have focused on model-centric and data-centric approaches. However, building a testing framework for LLMs, that are being widely used and adopted, needs to include another important aspect — the user. We, therefore, propose a testing framework that encompasses model, data, and human centered testing.
Our human centered approach is two-fold. First, the system should be designed with the user in mind and incorporate ethical principles such as fairness, transparency, and safety as well as create value for the user. Second, the system should learn from human input and collaboration to provide a better experience between the user and the machine.
In the first part of this blog, we cover testing the data and the model. This includes training a model from scratch or fine-tuning an existing (foundational) model. The second part will guide you through testing related to model integration and monitoring in production.
Data
The first step in proper LLM evaluation is the evaluation of the data. Datasets like C4, The Pile, The Bigscience Roots Corpus, and OpenWebText have helped immensely in providing representative data for the training of these models. However, checking them manually is close to impossible, so their quality might not be guaranteed. Therefore, validating the input data is an organization’s responsibility when training or fine-tuning language models.
"It is important to note that data validation varies immensely by use case, so problem formulation helps define which metrics to track as part of the testing strategy."
During data validation we should ensure data privacy and provenance are followed appropriately, data consistency is ensured, and bias & drift are mitigated and measured. Since the data carries all information to fine-tune the models, the data validation steps are extremely important to follow and track using data version control (DVC).
 Quality control for data testing
Quality control for data testingConsistency
After we remove PII (Personal Identifiable Information) and ensure our data is representative, we need to clean up the data and make it consistent so it can be used as training data. Given we are handling raw text with a lot of junk and gibberish — this is no easy feat. It can be accomplished through data cleaning techniques such as decontamination, de-duplication, removal of junk data, document length standardization, and more. Testing of these steps is done through data schema testing.
"The schema is comprised of several structural rules that all training data needs to comply with. For example, there should be no duplications, contaminated data, and HTML text. This can be done through similarity score comparisons or just simple length checks that need to adhere to a specific value."
Handling Private Information
As you should be aware, ChatGPT is being continuously trained on user prompts for purposes of alignment and improvement of the model (if consent is given). It is the team’s responsibility to not leak private information to the model during training and to ensure all controls are taken to prevent personal identifiable information (PII) from being used for training.
To address privacy concerns, there has been a growing body of research regarding privacy-preserving language models. Currently, the most obvious approach is to reduce the privacy risk by not training on any PII or protected health information (PHI) through data sanitization. Alternatively, modified algorithms can be used to reduce the memorization of private data through differential privacy.
"The first step in data sanitization is to find and identify the PII or PHI, this can be accomplished using various cloud based approaches (e.g. AWS, Microsoft Azure, Google Cloud) or other available PII detection tools like Octopii."
Bias
Like all generative models, LLMs suffer from a variety of harmful biases. These biases often find their origin in the training corpus. The model is trained to reflect the language in the training set as accurately as possible. As this data is often collected from various sources scraped from the internet, it is likely to contain prejudiced stereotypes we encounter every day. If worded incorrectly these stereotypes can cause unfair discrimination or social harm, further reinforcing them.
"Addressing and mitigating these biases is an ongoing challenge in the development of LLMs. We need to ensure we are reviewing the training data for underrepresented groups or biases. This can be done using Exploratory Data Analysis (EDA), and quantifying parity with Chi-square, ANOVA or similar statistical tests."
Toxicity
Besides stereotypes, the level of toxicity can be a harmful bias in language models concerning the choice of words. In most cases, we want models to answer in a polite everyday manner. But the internet is a semi-anonymous place, where foul language is much more common than in our daily life. We need to make sure we can control the answer a model gives, as it can result in discrimination when it affects certain groups in an unfavorable way. One approach to detect and mitigate toxic speech is to use Perspective API.

 Examples of toxicity. Source
Examples of toxicity. Source
Even non-toxic language can pose other problems, as language can be classified into agentic, communal, or gendered language. Agentic language is often preferred in organizations as it is perceived as more powerful, confident, and self-oriented. Communal phrasing tends to have a softer, harmonious, and collaborative tone. ChatGPT also tends to use agentic language, which can reinforce existing inequalities, such as gender inequality in fields like finance or STEM.
The Model
 Quality control for model testing
Quality control for model testing
Model performance tests
Traditionally, testing of language models is performed by using metrics such as word- and byte-perplexity. While still useful to develop language models, they are not sufficient in the current LLM paradigm. However, if you are developing a model from scratch, these metrics will be valuable in the initial stages of development. EleutherAI has provided a very extensive overview of such methods in their LM Evaluation Harness.
A more meaningful test strategy may be to perform task specific testing, using benchmark datasets. For instance, if you’re testing a question answering system, you can use a dataset like CoQA. Alternatively, you can use LAMBADA for word prediction, or HELLASWAG for sentence completion. In this section, we’ll focus on two metrics that we find of particular interest, namely biases and robustness. However, make sure to read up on general testing of LLM’s too.
Model bias testing
Benchmark datasets can be used to test for a variety of evaluation metrics. Specifically, for conversational text models, BOLD is a benchmark dataset which can be used to test for social biases. For example, the authors show that all tested models have a greater tendency to classify statements about science and technology to be male, whereas statements about healthcare & medicine are predominantly predicted as female. It shows popular models such as GPT-2 and BERT, on which your application or downstream tasks may depend, contain these biases too… ouch!
Model robustness testing
Another crucial metric to monitor is robustness. Given the large input space of language models, we cannot possibly test all inputs for our language model. This is where robustness testing comes in handy. Robustness refers to the performance gap of a model between seen and unseen data. For instance, concerning gender bias we can consider the following test prompt:
‘"he [man/woman] worked in the hospital as a doctor"
We’d like the predicted probability to be similar between ‘man’ and ‘woman’. If this is not the case, the model does in fact contain a gender bias. After tweaking the training data, we’ve managed to improve the prediction’s similarity. Great! However, the model just learned to mitigate bias in hospital settings, but it still finds the CEO in a different sector more likely to be a man. You can see where this is going…
To ensure fairness in a broader sense, adversarial testing is a technique which can help us get an idea of the robustness of our model in a more automated fashion. Through augmentation of existing test data, we can establish much broader test coverage for our models. For instance, by taking gendered sentences and substituting the gendered terms, we can get insight on which specific examples break our assumptions about the model’s gender biases and retrain the model in a targeted fashion.
"Adversarial testing can be applied much broader than that. TextAttack is a python package which implements adversarial example generation using several different methods. One of such implemented methods is TextFooler, an adversarial example generation algorithm which finds test cases that break the model through taking a true positive sample, replacing words that are highly contributing to this outcome with synonyms, or antonyms, and evaluating the effect of this replacement."
Human in the loop
As you might see, the possibilities of adversarial testing are endless, but there are some drawbacks to this method. For one, the current state of the art implementation of these attacks result in a lot of false positives. By using a little human intervention, we can curate the generated examples and create our own benchmark dataset.
This combination of adversarial example generation and model training is fittingly called adversarial training. Combined with a human-in-the-loop approach, it provides a human centered framework for testing and improving our model’s performance on almost any metric we can think of at the prediction level.
"Adversarial NLI and Squad Adversarial are some examples of datasets which are constructed using an automated method such as TextFooler, combined with a human-in-the-loop approach to remove false positives."
Furthermore, we need to make sure the model’s alignment corresponds with our human values. For example, a reinforcement learning (RL) agent may be able to learn to achieve a high score in a game, but it may not learn to play the game in a way that is fun or engaging for humans. We can use a novel method like reinforcement learning from human feedback (RLHF) to improve the accuracy, quality and ensure our models are properly aligned to be engaging and human-like. We will expand on this in part two of our playbook.
Conclusion
In this blog we’ve proposed a test strategy through a practical playbook, with methods that can be used to test the data and the model. However, it should be said that this is not a one-size-fits-all playbook. The techniques and suggested packages should be reviewed and revised based on the considered risks of your data, model, and application.
In the second part of the playbook, we introduce practical methods for testing the system and making it more user centric. We discuss topics such as prompt engineering, explainability, MLOps, and drift monitoring. Stay tuned!


![[Missing text '/pageicons/altmail' for 'English']](/Static/img/email.png)
+31347242046
+31347242046