
Having the right mindset for developing Machine Learning systems
The Machine Learning process in product development demands a different approach and mindset to how you’d build a more conventional software product.
In order to adopt this mindset, the most important thing to understand is that developing a Machine Learning system is more like a scientific process than a traditional software development process. However, the whole solution still requires a lot of software engineering practices. Let’s see how the processes differ.
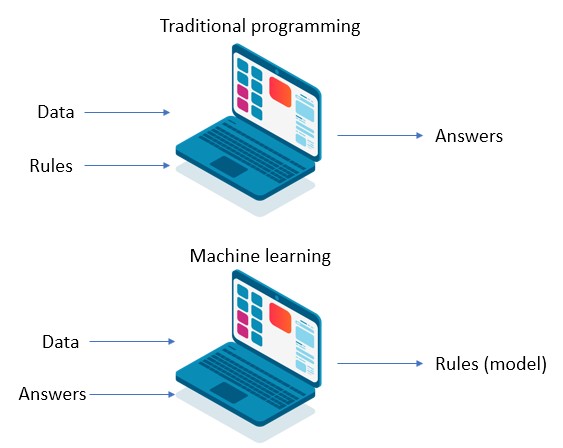
Machine Learning vs traditional programming
In traditional programming, you write down all the rules that the program needs to perform and accomplish for a specific task in order to produce the desired result. The program takes some data as input and this is then processed as stated by the rules. Hopefully, in the end, it will return the correct result. In contrast, a Machine Learning system is ‘trained’ rather than being programmed explicitly. The input to such a system is not just the data but also the expected result for that data and the output will then be a set of rules (this is also called a model in Machine Learning vocabulary).
An iterative process
This ‘training’ is the main difference from the software development process in that all the abilities of the Machine Learning system need to be learned along the way – you cannot design it upfront. It is this characteristic that forces the need for another style of working. It is a highly empirical and experiment oriented procedure in that we need to try and test things out in an iterative fashion before we know if the result is good enough.
There are many potential obstacles along the way. For example, there is always the risk that the data you have does not contain any predictive power, i.e. there is no signal that can be used to train the system. In this instance, we could go back to see if it is possible to find other data sources. But even if the data shows some promising results, we still need to iterate through different algorithms, different versions of the data, different settings of the model parameters(,) and so on in order to find the best possible model. All this is done by trial and error; you have a hypothesis and you try it out, you learn something new from the results and this generates a new set of ideas to try out in the next iteration.
One could argue that this process is basically an application of the scientific method. Therefore, it is often impossible to be able to say upfront if the trained Machine Learning system will be able to produce the desired outcome. This also makes it important to decide early how progress should be measured.
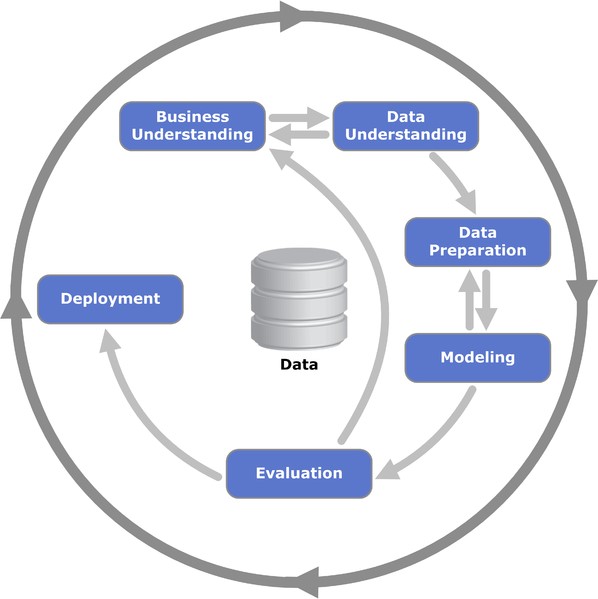
The CRISP-DM is one process model that describes the iterative process of building Machine Learning models. Kenneth Jensen / CC BY-SA (https://creativecommons.org/licenses/by-sa/3.0)
Uncertainty
There are several aspects that bring uncertainty into a Machine Learning project. First, you have the data itself that can vary in quality and be incomplete, for example with missing data points. How the data was gathered and if the sample is a good representation of the problem domain also matters. Then, of course, the models themself are imperfect because they were built from such data.
There is also uncertainty in terms of estimating a timescale. That’s because you will undoubtedly find things along the way that you did not expect, so you need to reconsider previously made choices. You need to experiment and try things out in order to see if you are on the right track. Also, depending on the size of the data and the complexity of the model, the training phase can take from hours to days until you can test the new version. Then depending on the result, it could be back to the drawing board. This is the reason why it can be difficult to give a proper time estimate. There are so many unknowns involved, and new clues unfold for every iteration.
There should, of course, be a time frame set for the project, and this is important, but you still cannot guarantee that the project will be successful within this time frame. However, it will rarely be a waste of resources no matter the result, because you will learn a lot along the way, and this will be valuable for taking the next step in the right direction.
Conclusion
Machine Learning is not like any other technology but it is, in many cases, the only technology that can solve certain problems. We need to ensure that everyone involved in the project has a common understanding of what is required, how the process works, and that we have a realistic view of what is possible with the tools at hand. To boil down all this to its core components we should consider a few important rules:
- Create a common ground of understanding to ensure the right mindset
- State early on how progress should be measured
- Communicate clearly how different Machine Learning concepts work
- Acknowledge and consider the inherited uncertainty – it is part of the process
This post is just touching the surface on all the different aspects that one must consider in an AI project, see it more like an introduction and short overview. Still, I hope this helps to bring some clarification on how these kinds of projects go about and what to consider before starting out. Happy Machine Learning!
References and Resources
Forde, J. Z., & Paganini, M. (2019). The scientific method in the science of machine learning. arXiv preprint arXiv:1904.10922. https://arxiv.org/pdf/1904.10922.pdf
https://machinelearningmastery.com/uncertainty-in-machine-learning/
https://www.snaplogic.com/blog/the-ai-mindset-bridging-industry-and-academic-perspectives
https://www.jeremyjordan.me/ml-projects-guide/
https://blog.floydhub.com/structuring-and-planning-your-machine-learning-project/
Get in touch
For an informal chat about your Machine Learning projects, get in touch with Michael Ohlsson, SogetiLabs, Sweden


![[Missing text '/pageicons/altmail' for 'English']](/Static/img/email.png)
+46 72-214 96 86
+46 72-214 96 86